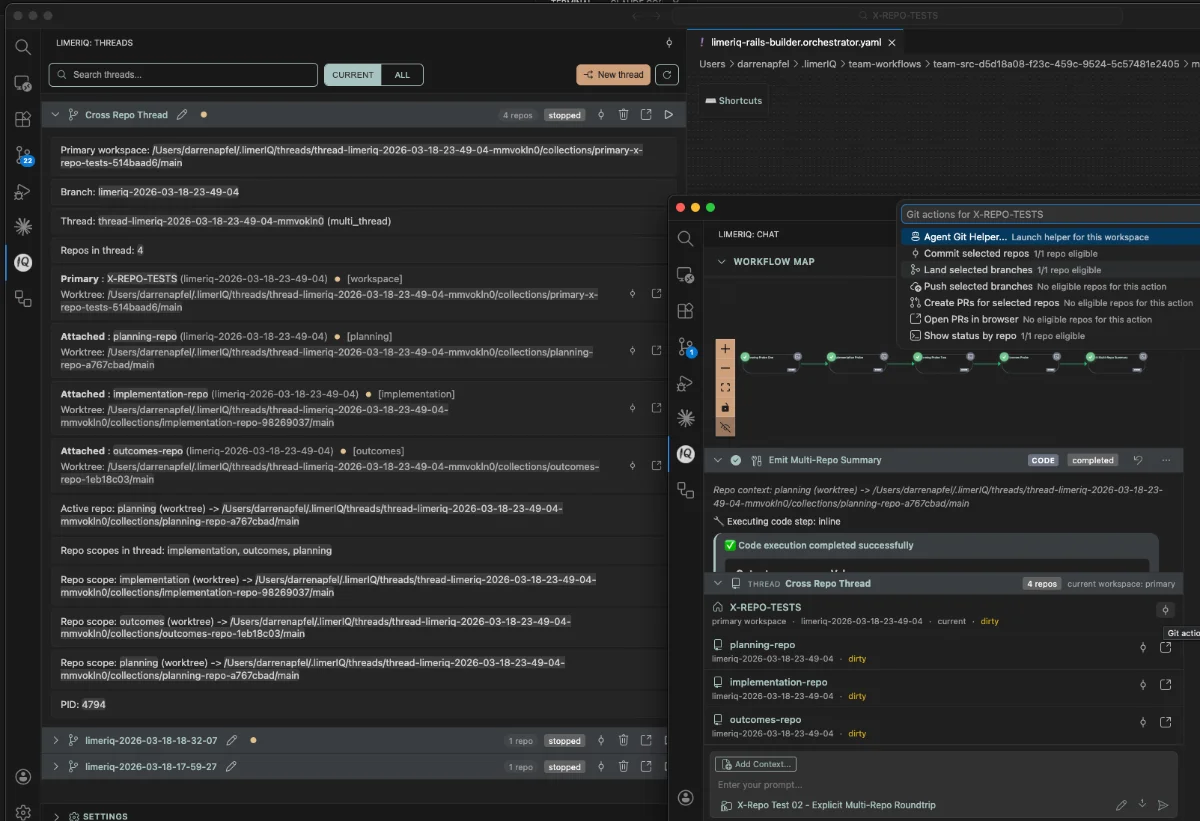
Most agent tools still treat instructions like polite suggestions. limerIQ now lets you turn them into enforceable contracts.
There is a pattern you start seeing once you have watched enough agent runs:
the agent sounds confident, the transcript looks productive, the summary seems plausible, and the actual workspace tells a different story.
The file was never written.
The output shape was wrong.
The test command never ran.
The workflow "completed" anyway.
This is one of the core reasons AI-assisted software delivery feels exciting and fragile at the same time. The generation is impressive. The compliance is optional.
We wanted to fix that at the workflow layer.
That is what the new guardrails are for.
Instructions Are Not Controls
The old way to steer an agent was mostly rhetorical:
- remind it what files to touch
- ask it to return structured output
- tell it to run tests
- hope it notices when it missed something
That is not governance. That is wishful prompting.
If you want a workflow to be reliable, the runtime needs a way to check the work after the model stops talking. It needs to compare the claim against the workspace, the outputs, and the execution context. If the step failed the contract, the workflow should say so clearly.
limerIQ now gives you several ways to do that.
The First Layer: Required Outputs
The most basic guardrail is still one of the most important: required outputs.
If a step says it will return a test summary, a risk rating, a handoff packet, or a deployment decision, that output can be marked as required. Missing it is not a soft suggestion. It is a compliance failure.
That sounds obvious, but it matters because missing outputs are one of the fastest ways for workflow state to decay. Downstream steps start making decisions from empty variables, partial summaries, or guessed context. Once that happens, the whole run can drift while still looking "green" from the outside.
Required outputs stop that drift early.
The Second Layer: Expected File Actions
This is where guardrails start feeling concrete.
With expected_files, a step can declare the files it is supposed to create or modify. If the step completes and the workspace does not match the declared expectation, the runtime catches it.
This is the missing bridge between "the model said it updated the docs" and "the docs actually changed."
For software delivery, that matters everywhere:
- specs that should have been written
- migration files that should exist before rollout
- test files that were promised but never created
- handoff docs that downstream steps are waiting on
It also matters for trust. If the workflow says a step is complete, the artifacts should exist where the workflow said they would exist. Anything less is just a nice transcript.
The Third Layer: Self-Healing Retry Loops
Hard failure is better than silent drift, but it is still not ideal.
Sometimes the model simply missed a requirement on the first pass. It forgot one file. It returned output in the wrong shape. It skipped a detail that was clearly requested.
That is why limerIQ also supports max_resume_attempts.
If a step fails compliance, the runtime can resume the same step with a targeted prompt describing what was missing. The point is not to give the agent infinite retries. The point is to preserve context and give it a chance to repair the exact issue instead of forcing a human to restart the whole flow.
That is a much better model for long-running delivery workflows.
It means a run can fail closed without failing dumb.
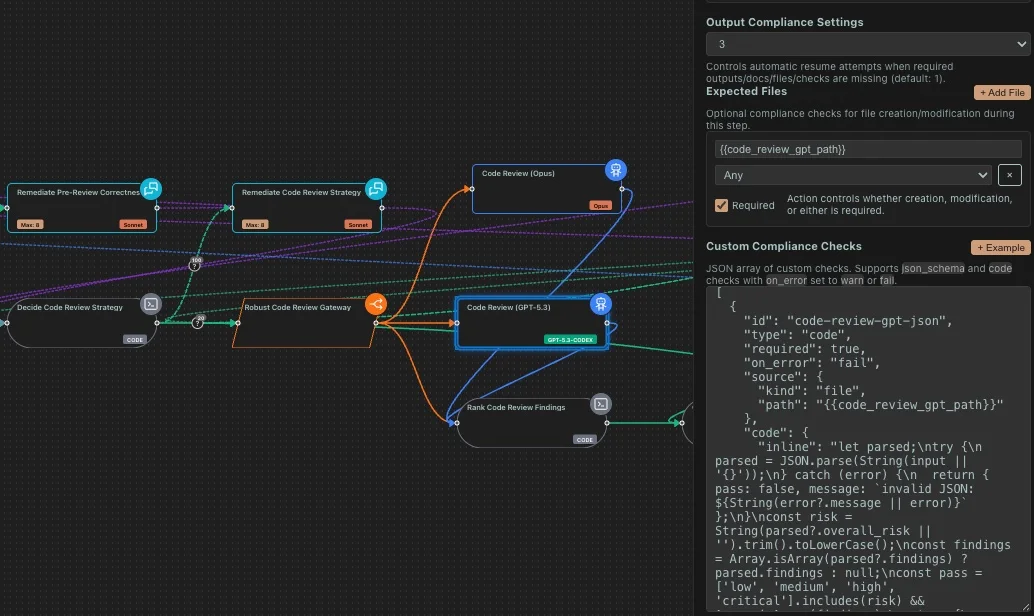
The Fourth Layer: Structured Compliance Checks
This is the bigger leap in the new system.
limerIQ now supports compliance_checks on a step, including JSON-schema validation and code-based checks.
That means a step can be judged not only on whether it returned something, but whether what it returned or wrote is structurally and semantically acceptable.
A JSON-schema check is useful when the output needs to match a real contract: a handoff payload, a release packet, a metadata document, a manifest.
A code-based check is useful when structure is not enough. Sometimes the question is not "is this valid JSON?" It is:
- does this file contain the required linkage IDs?
- did the step update the right paths?
- does this artifact satisfy a custom team policy?
- should this issue block the run or warn and continue?
That is where code guards matter. They let teams write their own deterministic test for what "acceptable" means.
This is the moment guardrails stop being a product checkbox and start becoming infrastructure.
Soft Guards Matter Too
Not every rule should be a hard blocker.
That is another place older AI workflow tooling gets clumsy. It tends to collapse everything into either "ignored" or "fatal." Real delivery is rarely that clean.
Sometimes you want a check to warn without blocking:
- an artifact exists but looks suspicious
- a non-critical convention was missed
- a review note should follow the run forward
limerIQ supports that shape too. A code-based compliance check can warn and proceed. The point is not rigidity. The point is that the workflow author gets to decide which failures are terminal and which are advisory.
That is how governance becomes usable in practice.
Guardrails for Parallelism
Guardrails also matter when the workflow itself becomes dynamic.
If a workflow is spawning parallel work at runtime, you need limits. Otherwise the execution graph can explode because a model had an ambitious idea about how many branches would be "helpful."
That is why limerIQ also supports parallel guardrails like maximum parallel instances and total instance limits. These are not just performance tuning knobs. They are safety controls for agentic execution.
The product implication is simple: autonomy should have boundaries before it has enthusiasm.
Why This Changes Headless Runs
Guardrails are useful in an interactive session. They become essential once the workflow is running unattended.
If a workflow is executing overnight, in CI, or on a self-hosted runner, nobody is sitting there to notice that the model never actually wrote the contract file or silently skipped a verification step. The runtime has to notice.
That is where the new guardrails really earn their keep.
They let you move from:
"I hope the agent did the thing"
to:
"the workflow verified whether the thing happened, retried the step when it did not, and stopped if the contract was still unmet."
That is a much stronger foundation for any kind of autonomous delivery.
The Bigger Point
This feature is not really about validation syntax.
It is about redefining what a workflow step is allowed to claim.
In a governed system, a step is not done because the model said "done." It is done because the runtime can verify the outputs, the files, and the compliance conditions that define success.
That sounds stricter because it is stricter.
It is also the only way AI execution starts to feel trustworthy outside a demo.