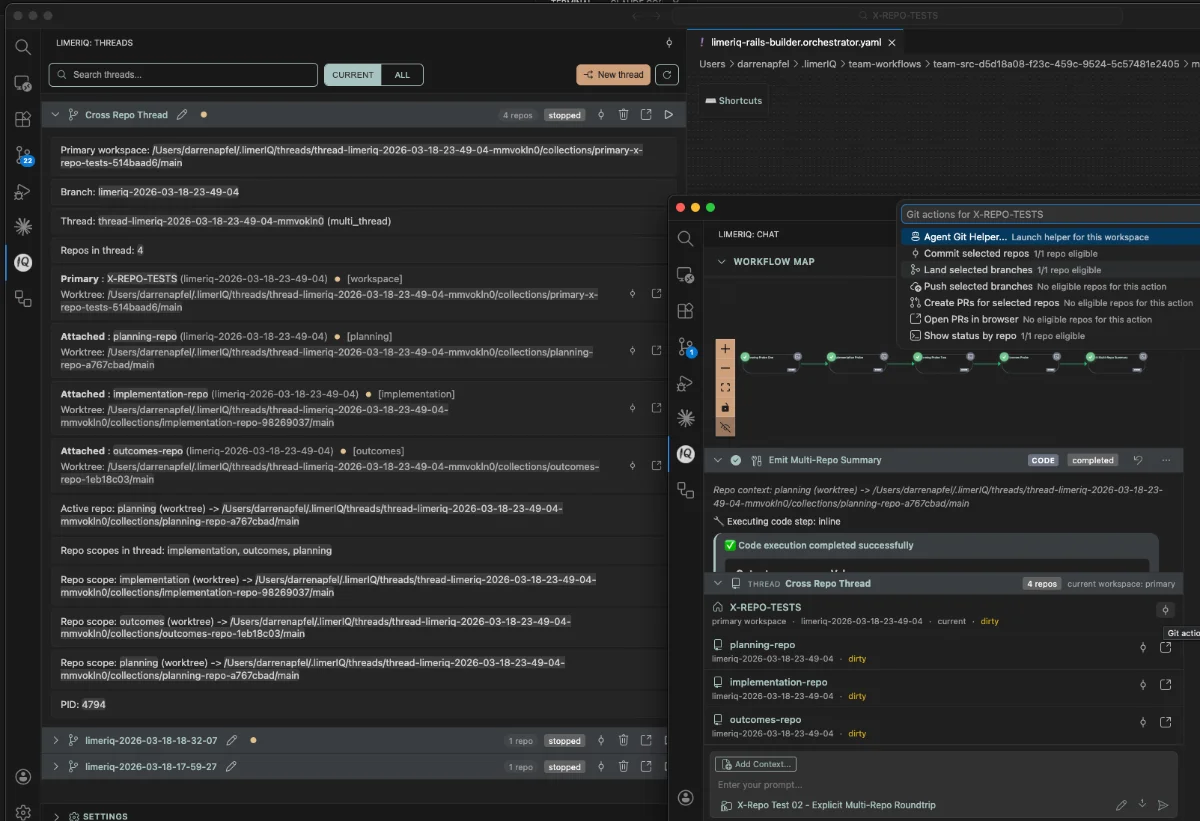
Real changes cross boundaries: product intent, implementation, infra, docs, tests, and release automation. limerIQ can now route work across those boundaries on purpose.
Single-repo demos have distorted how a lot of people think about AI coding tools.
They make it seem like the important problem is getting one model to make a set of edits inside one repository.
That is a real problem, but it is not the whole job.
Real delivery crosses boundaries constantly:
- a requirement starts in one repo and drives implementation in another
- a backend change requires infra updates somewhere else
- documentation, tests, release pipelines, and migration plans all live in different places
- a "simple" change becomes an initiative the moment it touches more than one system
If your workflow engine cannot understand that, it cannot really govern delivery. It can only govern one room in the building.
That is why cross-repo orchestration matters so much in this release.
The Problem With Single-Repo Agent Loops
A lot of AI workflows quietly assume the repo they started in is the repo that matters.
That assumption breaks quickly.
You can see it in the failure modes:
- the agent writes the right thing in the wrong repo
- the workflow handoff loses context when moving to another codebase
- the user has to manually restate where the next phase should happen
- multi-repo changes get flattened into ad hoc shell scripts and vibes
At that point the workflow is not really orchestrating delivery. It is improvising around repository boundaries.
We wanted limerIQ to treat those boundaries as first-class structure.
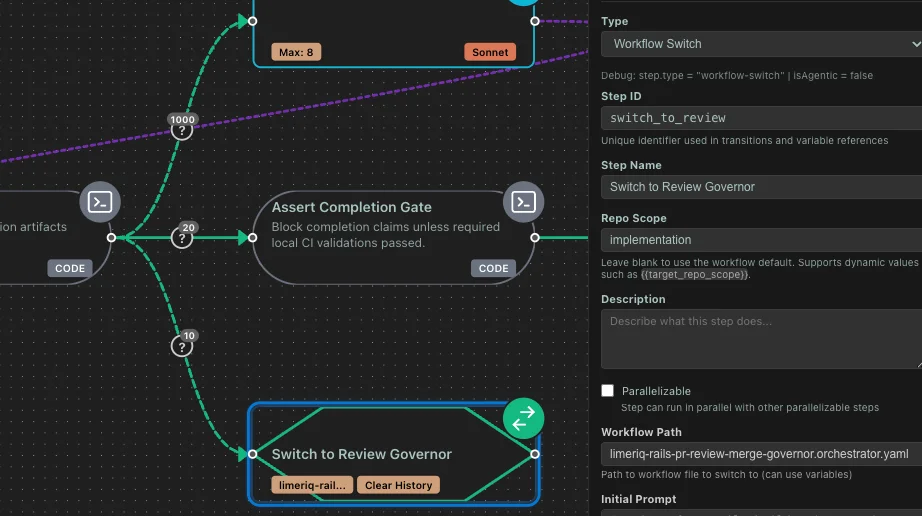
Repo Scopes Make the Routing Explicit
The key mechanism is repo_scopes.
At the workflow level, limerIQ can define a repo map for the run and set a repo_scope_default. At the step level, a step can declare its own repo_scope, including dynamic values that resolve at runtime.
That sounds like a small configuration detail, but it changes the entire execution model.
Instead of assuming every write happens in the current workspace, the workflow can say:
- this step belongs in the planning repo
- this one belongs in implementation
- this verification step should run against infrastructure
- this downstream workflow should continue in the target repo scope we just resolved
Now the routing is explicit, inspectable, and enforceable.
That is the difference between cross-repo support as a marketing phrase and cross-repo support as runtime behavior.
Workflow Switching Without Context Loss
Cross-repo execution is not only about individual steps.
Sometimes the right shape is to chain workflows, where one workflow resolves the next repo context and hands the work forward. That is why workflow switching matters here too.
limerIQ can carry runtime handoff context like REPO_CONTEXTS_JSON and target_repo_scope into the next workflow so the downstream phase does not have to rediscover the world from scratch.
This matters because the worst version of multi-repo automation is the one where every phase behaves like a fresh chat with amnesia.
The whole point of orchestration is that context survives the transition.
Multi-Repo Safety Should Happen Before Step 1
Another important detail: policy enforcement needs to happen early.
If a workflow is about to touch paths outside the current run directory, the user should not find that out halfway through the execution. The system should decide up front whether the run is allowed to proceed under the active policy.
limerIQ now treats that as a precondition, not a surprise.
That matters for trust. Multi-repo work is powerful, but it is also one of the fastest ways to create blast radius if the system gets casual about where it is allowed to write.
Explicit routing and early policy checks are what keep this from turning into a very confident version of "hope for the best."
Threads Make Multi-Repo Feel Like One Run
Cross-repo support also gets much better once it is paired with Threads.
The important product decision here is that one thread can own one primary workspace and attach additional repo worktrees as needed. That means a multi-repo workflow still feels like one coherent execution context, not a pile of disconnected sessions.
That is the right mental model for real delivery.
When a workflow crosses from repo A to repo B to repo C, the user should still feel like they are following one piece of work through its lifecycle. The system can manage the attached worktrees and manifests underneath. The product surface should stay coherent.
That is exactly what the thread model is for.
The Real Use Cases
This feature matters because the interesting workflows are almost never confined to one codebase.
Think about:
- initiative bundles that span planning, implementation, and release repos
- PR guard flows that need to inspect app code, tests, and deployment policy
- migrations that update services, schemas, docs, and rollout artifacts together
- CI triage that diagnoses a failure and then routes the fix into the correct codebase
These are not edge cases. This is the shape of actual software delivery.
If AI is going to help govern that work, the workflow engine has to understand where the work belongs at each stage.
The Bigger Point
Cross-repo support is not just a convenience feature for advanced users.
It is one of the clearest signs that limerIQ is moving beyond "tool for getting better results from coding agents" and toward "execution layer for delivery systems."
Because delivery systems are cross-repo by default.
They cross codebases, environments, teams, and approval boundaries. A workflow engine that understands only one working directory cannot own that job.
limerIQ can now start to own it.