The Cost of Context: Optimizing AI Token Usage in Enterprise Workflows
Demonstrates strategic model selection and thinking level optimization for enterprise AI workflows. This workflow intelligently routes requests through cost-optimized paths—using lightweight triage fo
Target Audience: Enterprise Architects, Staff Engineers
The Hidden Cost Problem
Every AI interaction consumes tokens. At small scales, this cost is invisible. At enterprise scale, with hundreds of workflows running daily across multiple teams, token costs become a significant line item. A naive approach of using the most capable model for every task can multiply costs by 10x or more without proportional quality gains.
The challenge is not simply choosing cheaper models. It is understanding which tasks genuinely require premium reasoning and which can be accomplished with lightweight inference. Get this wrong in either direction and you either waste money or sacrifice quality.
The Strategic Model Selection Framework
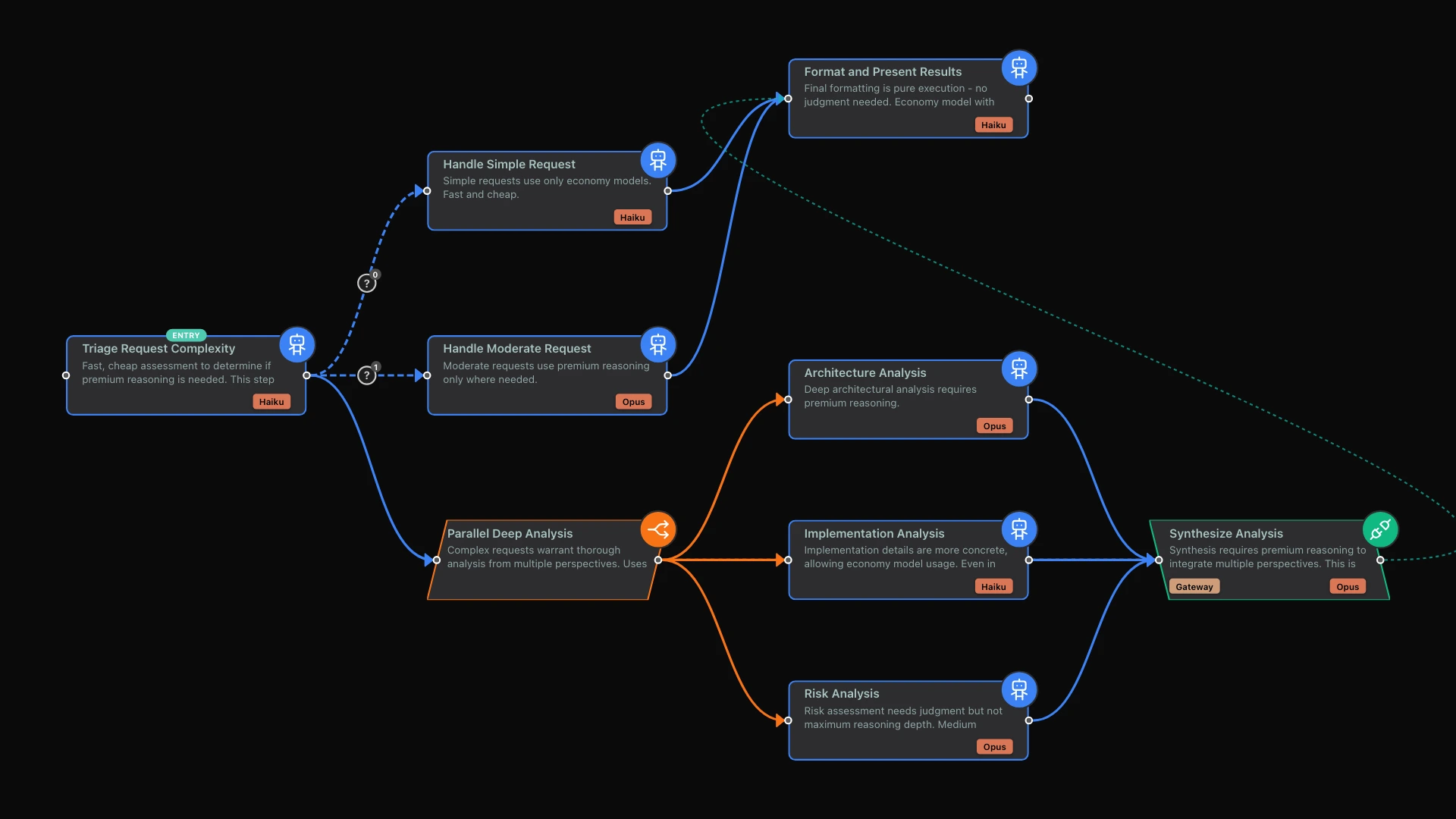
limerIQ enables per-step model selection within workflows, allowing you to match model capability to task complexity. Through the visual workflow editor, you can assign different models to different steps based on what each task actually requires.
The framework follows a simple principle: use premium models for judgment, economy models for execution.
The Two-Tier Strategy
Top-tier models excel at complex architectural decisions, ambiguous problem analysis, multi-factor trade-off evaluation, synthesis and integration steps, and user-facing communication. These are tasks where the quality of reasoning directly impacts outcomes.
Economy-tier models handle well-specified implementation tasks, template-based generation, straightforward validation checks, formatting and transformation, and documentation from clear specifications. These are tasks where the requirements are clear and the output format is well-defined.
The middle tier offers diminishing returns. You pay more than economy models but rarely get meaningfully better results than top-tier models on complex tasks. Avoid the middle unless specific constraints require it.
Thinking Levels: The Overlooked Multiplier
Model selection is only half the equation. How much reasoning the model applies before responding directly impacts both cost and quality.
High reasoning involves extended reasoning chains, consideration of multiple approaches, and explicit trade-off analysis. This level is best for architecture decisions, debugging complex issues, and synthesis tasks.
Medium reasoning provides balanced depth, considering obvious alternatives without exhaustive exploration. This level suits code review, documentation, and planning tasks.
Low reasoning generates direct responses with minimal deliberation. This level works well for simple tasks, formatting, and validation.
The cost differential is substantial. A step with premium models and high reasoning may cost 5-10x more than the same step with low reasoning. For tasks that do not benefit from extended deliberation, you are paying for thinking that produces no improvement.
The Model Escalation Pattern
Not every task requires the same model throughout its execution. Some tasks appear simple initially but reveal complexity upon analysis. The escalation pattern handles this gracefully.
In the visual workflow editor, you design an initial assessment step using a lightweight model. This step analyzes the request and determines its complexity. Based on that assessment, the workflow routes to different subsequent steps: simple requests go to economy models, moderate requests to standard models, and complex requests to premium models.
This pattern uses a lightweight model to triage incoming requests, then routes to appropriately capable models. Simple requests never touch premium models. Complex requests get the reasoning power they need. The result is cost optimization without quality sacrifice.
Cost-Per-Step Analysis
Consider a typical enterprise workflow: code review with security, performance, and correctness analysis.
An "all premium" approach might cost around $1.20 per run. Every step uses top-tier models with high reasoning, regardless of whether that reasoning adds value. At 100 daily runs, monthly costs reach $3,600.
A strategic selection approach might cost around $0.65 per run. Context gathering uses economy models because collecting information does not require deep reasoning. Security analysis uses premium models with high reasoning because catching vulnerabilities is worth the investment. Performance review uses premium models with moderate reasoning. Correctness checks use economy models because the criteria are well-defined. Synthesis uses premium models because combining findings requires strong reasoning. Result presentation uses economy models because formatting the output is straightforward.
The strategic approach costs 46% less while maintaining quality where it matters. Security analysis still uses premium reasoning. Synthesis still applies high thinking. But context gathering and result presentation do not need that investment.
Task-to-Model Mapping Guidelines
When assigning models to workflow steps in the visual editor, consider these questions:
Is the task novel or ambiguous? If yes, use top-tier models with high reasoning. Ambiguity requires exploration, and exploration requires capability.
Does the task require judgment or trade-off analysis? If yes, use top-tier models with medium reasoning. Trade-offs benefit from considered deliberation but may not need exhaustive analysis.
Are the requirements crystal clear? If yes, economy models with medium reasoning are sufficient. Clear requirements mean the model needs to execute, not decide.
Is the output template-like or simple formatting? If yes, economy models with low reasoning will suffice. Formatting is mechanical, not cognitive.
Specific Task Recommendations
Architecture decisions warrant premium models with high reasoning because these choices cascade through everything that follows. Code implementation can use economy models with medium reasoning because clear specifications reduce the need for exploration. Security analysis demands premium models with high reasoning because the cost of missing vulnerabilities far exceeds the cost of thorough analysis.
Performance review benefits from premium models with medium reasoning. Test generation can use economy models with medium reasoning when the test scenarios are well-defined. Documentation writing from clear specifications can use economy models with low reasoning. Formatting and cleanup tasks use economy models with minimal reasoning.
User interaction benefits from premium models with medium reasoning because communication quality matters. Synthesis and integration steps warrant premium models with high reasoning because combining multiple inputs into coherent output is cognitively demanding.
Parallel Execution and Cost
When workflows branch into parallel paths, costs multiply. Four branches running simultaneously use four times the tokens. This makes strategic model selection even more critical in parallel contexts.
Best practices for parallel cost optimization: Foundation steps that set up the parallel branches should use economy models because the baseline setup does not need premium reasoning. Branch steps should match model capability to branch complexity because not all branches need the same capability. Integration steps that synthesize parallel results should use top-tier models because synthesis requires strong reasoning.
Monitoring and Optimization
limerIQ tracks token usage per step, enabling cost attribution and optimization. Use this data to identify expensive steps, challenge model choices, experiment with downgrades, and measure quality delta.
Identify which steps consume the most tokens. Question whether premium models are earning their cost on those steps. Try economy models on medium-complexity tasks and measure whether quality suffers. Track outcome quality against model choice to build institutional knowledge about what actually matters.
Create feedback loops. When a step consistently succeeds with a lighter model, codify that choice in your workflow templates. When steps fail due to insufficient reasoning, escalate the model selection and document why.
The Enterprise Rollout Strategy
For organizations deploying limerIQ at scale, a phased approach to cost optimization works best.
Phase 1: Baseline Measurement. Deploy with consistent model selection across all steps. Measure costs and quality outcomes. Establish benchmarks before optimizing.
Phase 2: Targeted Optimization. Identify the highest-cost workflows. Apply strategic model selection to those workflows first. Measure cost reduction and verify quality maintenance.
Phase 3: Codification. Document model selection guidelines based on your experience. Create workflow templates with optimized defaults. Train teams on cost-aware workflow design.
Phase 4: Continuous Optimization. Monitor cost trends over time. Adjust as new models become available (new economy options may outperform old premium ones). Refine guidelines based on accumulated experience.
The ROI of Strategic Selection
Organizations that implement strategic model selection typically see 40-60% reduction in AI costs without quality degradation on the tasks that matter.
The savings come from multiple sources: economy models on simple tasks, reduced reasoning on straightforward operations, escalation patterns that avoid premium costs for trivial requests, and parallel execution optimization that prevents cost multiplication.
These savings are not one-time. They compound as workflow usage grows. An organization running 1,000 workflows daily realizes dramatically different cost trajectories depending on whether they use strategic selection or uniform premium models.
Conclusion
AI token costs at enterprise scale demand strategic attention. The solution is not wholesale downgrades but intelligent matching of model capability to task requirements.
limerIQ provides the tooling for per-step model selection, reasoning level configuration, and escalation patterns through an intuitive visual editor. Combined with cost monitoring, enterprises can reduce AI expenditures by 40-60% while maintaining quality where it matters.
The key insight is that not every token is created equal. Tokens spent on deep reasoning for architectural decisions earn their cost many times over. Tokens spent on premium models for formatting tasks are simply wasted. Strategic selection puts your AI budget where it creates value.
Next Steps:
- Explore the cost-optimization workflow templates in the limerIQ marketplace
- Audit your existing workflows for model optimization opportunities
- Establish cost baselines before optimization
Related Articles: