Two Models Are Better Than One: Competitive Execution with LLM-as-Judge
Leverage the strengths of multiple AI providers by running Claude and GPT-5.2 in competitive parallel analysis of your code. An LLM-as-Judge synthesis step automatically combines the best insights fro
When you ask a single AI model to review code, write documentation, or make architectural decisions, you get one perspective. It might be good. It might miss things. You have no way to know what you are not seeing.
What if you could get two independent perspectives from different AI providers, then have a third evaluate and synthesize the best insights from both? This is competitive execution with LLM-as-Judge, and it represents one of the most powerful patterns available in limerIQ.
Why Two Models Beat One
The premise is simple: different AI models have different strengths, training data, and reasoning patterns. Claude might excel at nuanced communication and edge case identification. GPT might catch architectural issues that Claude misses. Neither is universally better -- they are different.
When you run them in parallel on the same task:
- You get broader coverage - Each model catches things the other misses
- You identify high-confidence findings - When both models agree, you can trust that finding
- You reduce bias - No single model's blind spots dominate
- You build in quality assurance - The synthesis step forces critical evaluation
This is not theoretical. limerIQ's own planning system uses this pattern extensively. The robust intent-to-plan handoff workflow runs Claude and GPT in parallel for intent scoping, spec writing, architecture design, and plan review. The results consistently outperform single-model approaches.
How Competitive Execution Works
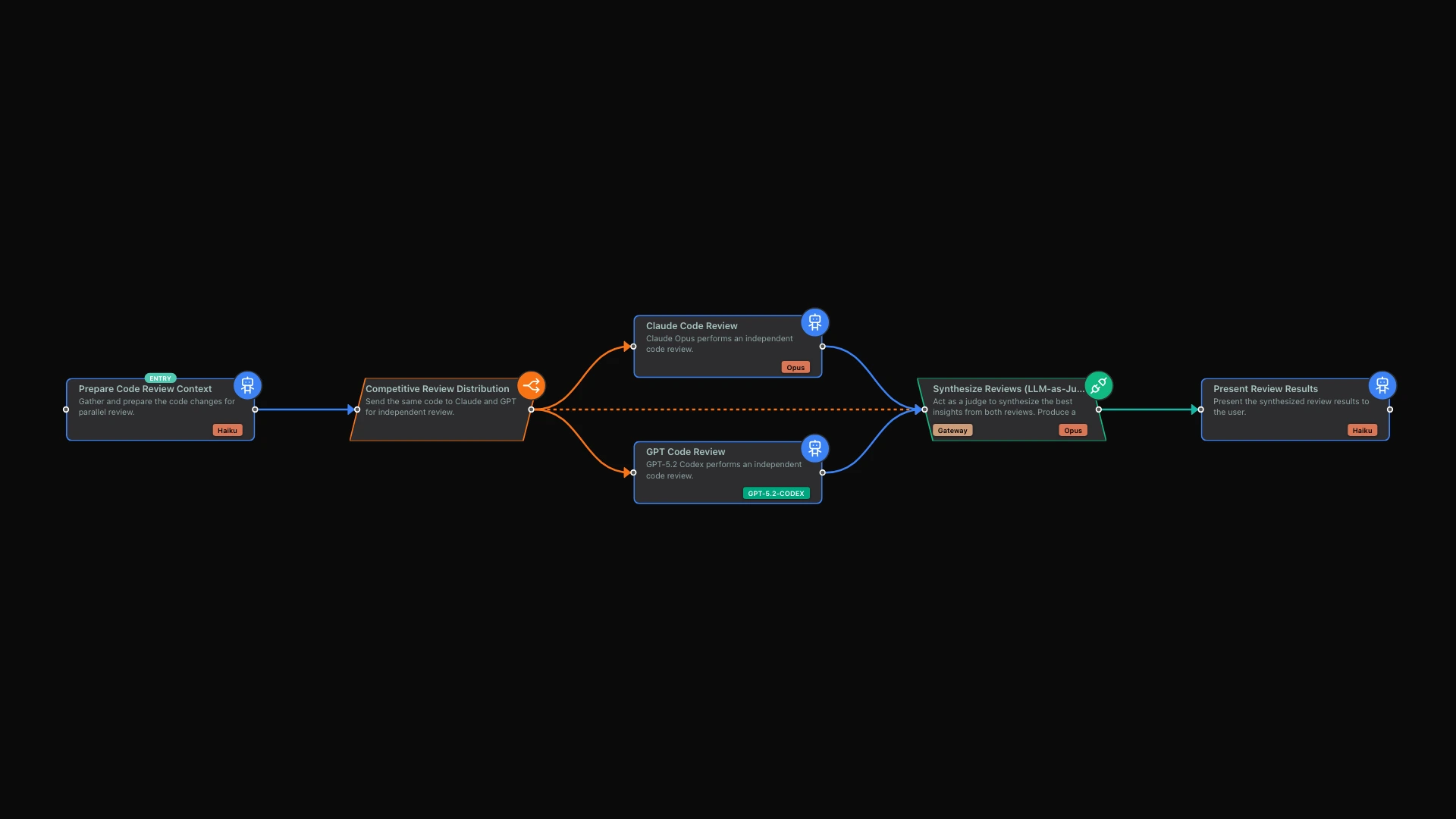
The visual workflow editor makes setting up competitive execution straightforward. You create a workflow with three main phases:
Phase 1: Parallel Distribution
First, the system takes your task and distributes it to two independent AI reviewers. In the workflow editor, this appears as a branching point where a single path splits into two parallel tracks. Each track runs simultaneously, with neither model aware of what the other is producing.
Phase 2: Independent Analysis
Each AI model performs its analysis completely independently. You might assign Claude with high reasoning capability to one branch, focusing on code quality and user experience implications. Meanwhile, GPT with extended thinking handles the other branch, perhaps with a security-focused perspective.
The key insight is that these analyses happen in true parallel -- not sequentially. Both models work simultaneously, so the wall-clock time is the same as running just one model, but you get two complete, independent perspectives.
Phase 3: LLM-as-Judge Synthesis
This is where the magic happens. A third step receives both analyses and acts as the judge. Its job is not to pick a winner, but to synthesize the best insights from both perspectives:
- Identify consensus findings (high confidence -- both reviewers agree)
- Resolve conflicts by making informed judgment calls
- Capture unique insights that only one reviewer identified
- Produce a prioritized, actionable final output
The synthesis step produces a review that is more thorough than either individual review because it elevates areas of agreement, forces explicit reasoning about disagreements, and preserves valuable unique insights from each perspective.
Real-World Results
When limerIQ's planning workflows use competitive execution, we consistently see:
More comprehensive coverage: GPT often catches performance implications that Claude underweights. Claude often identifies user experience and communication issues that GPT glosses over. Together, they find more.
Higher confidence in findings: When both models flag the same security issue, you can treat it as a definite problem. When only one model flags something, the synthesis step evaluates whether it is a real concern or a false positive.
Better documentation: The synthesis step forces clear articulation of what was found and why it matters. The resulting documents are more useful than either model's raw output.
Reduced review cycles: Because competitive execution surfaces more issues upfront, fewer problems slip through to later review cycles. Teams report catching 30-40% more issues in automated review than with single-model approaches.
Setting Up Competitive Execution in the Visual Editor
The visual workflow editor makes this pattern accessible without any coding. Here is what the process looks like:
- Open the workflow editor and create a new workflow
- Add a preparation step that gathers context about what needs to be reviewed (this can use a fast, economical model)
- Add a parallel gateway that branches into two paths
- Configure each branch with a different AI provider and optionally different personas (like "software engineer" vs "security engineer")
- Add a synthesis step that merges the branches and produces the final output
- Connect to downstream steps that act on the synthesized findings
The visual representation makes the parallel structure immediately clear. You can see at a glance that two analyses will run simultaneously, then converge at the synthesis point.
When to Use Competitive Execution
Competitive execution is most valuable when:
- The stakes are high - Architecture decisions, security reviews, production deployments
- You need confidence - Consensus findings carry more weight than single-model outputs
- Multiple perspectives matter - Code review, documentation, design decisions
- You want quality assurance built in - The synthesis step is an automatic quality gate
It is less necessary for:
- Simple, well-defined tasks with clear right answers
- High-volume, low-stakes operations where cost matters more than thoroughness
- Tasks where speed is critical and one model's output is sufficient
Cost Considerations
Running two models in parallel costs roughly twice as much as running one. But consider the full picture:
- Both branches run simultaneously - Wall-clock time is the same as single-model execution
- Higher quality reduces rework - Catching issues early saves expensive fixes later
- You can mix model tiers - Use a premium model for one branch, a standard model for another
- Synthesis adds value - The judge step produces better output than either input alone
For critical workflows where quality matters, the cost is easily justified by the improved outcomes. Many teams report that the reduction in rework and escaped defects more than pays for the additional AI costs.
A Practical Example: Automated Code Review
Consider how competitive execution transforms code review. A developer submits a pull request. Your workflow:
- Gathers context about the changes -- which files were modified, what type of changes were made, key areas of concern
- Sends the same review task to Claude and GPT simultaneously, with Claude focusing on readability and maintainability while GPT focuses on performance and security
- Receives both complete reviews within about the same time as a single review would take
- Synthesizes the findings into a prioritized list with consensus items marked as high-confidence
- Produces a final review that is more thorough than any single reviewer could produce
The developer receives a review that benefits from two distinct perspectives, with clear indication of which findings both reviewers agreed on versus which were unique observations.
What is Next
Competitive execution is just one of the advanced patterns limerIQ enables. Other articles in this series cover:
- Worktree isolation - How parallel branches get their own isolated filesystems for conflict-free development
- Consensus voting - When you need team agreement, not just synthesis
- Sprint gateways - Iterative execution across multiple development sprints
The common thread is that orchestrating multiple AI perspectives produces better outcomes than relying on any single model. limerIQ makes these patterns accessible through visual workflow design.
Two models really are better than one.